
%20(1).png)
One Platform to Secure your AI Stack
Pillar is the only AI security platform where business context connects discovery, testing, and protection — so security intelligence compounds across your entire AI lifecycle.
Security for AI that Focuses on What Really Matters







How Pillar Works

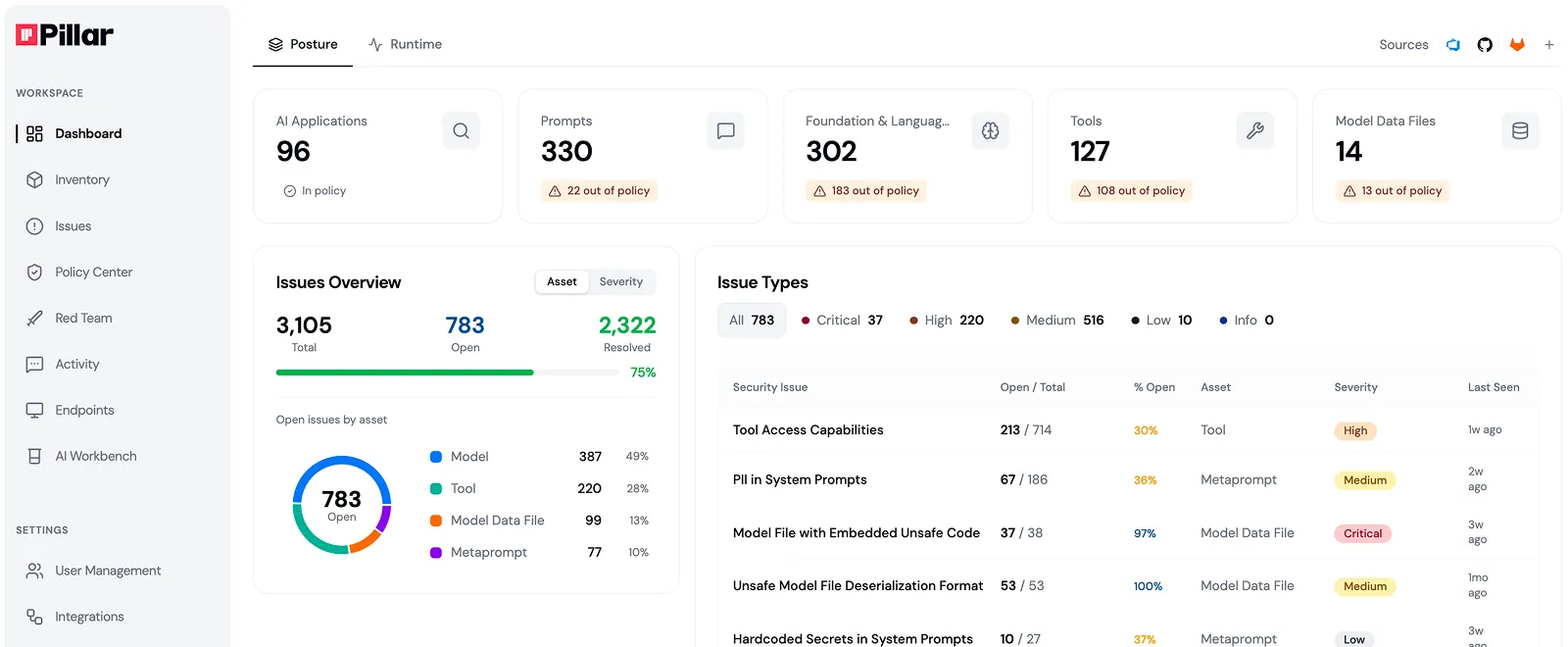
What AI agents exist in my environment?
Full inventory of agents, models, MCP servers, and tools — including shadow AI.
What can each agent actually access and do?
Maps instructions, data sources, tool permissions, and external connections per agent.
Which agents are handling sensitive data without approval?
Identifies agents with access to PII, code repos, production DBs, or financial systems.
Are unapproved AI tools running in my org?
Detects shadow coding agents, personal automation platforms connected to corporate data.
What is my overall AI risk posture?
Continuous risk scoring across all AI assets based on permissions, data access, and business exposure.
Which agents have excessive permissions?
Flags wildcard permissions (s3:*), missing HITL, and agents with unrestricted production write access.
What changed in my AI environment?
Tracks new agents, permission changes, and new tool connections since last known good state.
Where are my real attack paths — not just model vulnerabilities?
RedGraph maps how tools, prompts, and data combine to create exploitable surfaces specific to your environment.
Can an attacker pivot from one agent to sensitive systems?
Simulates lateral movement — e.g. support chat → Search skill → unauthorized SQL queries on your production DB.
What vulnerabilities only appear in production context?
Tests multi-turn attacks, tool hijacking, and indirect prompt injection through real agent configurations.
Is my agent behaving as intended right now?
Behavioral monitoring flags deviations from each agent's defined business purpose — not generic anomaly detection.
Is sensitive data leaving my environment?
Taint analysis traces PII and secrets from source to destination — blocks unauthorized egress in real time.
Are guardrails calibrated to each app's business purpose?
Adaptive guardrails adjust per agent — fewer false positives because they know what the agent is supposed to do.
Which AI tools are compliant with policy?
Enforces approved model lists, MCP allowlists, and AI usage policies across the full lifecycle.
Can I demonstrate AI security posture to auditors?
Audit logs, compliance reports, and policy lifecycle management for GDPR, CCPA, and internal standards.
What's my AI policy coverage gap?
Identifies agents operating outside governance boundaries before they become incidents.
What AI agents exist in my environment?
Full inventory of agents, models, MCP servers, and tools — including shadow AI.
What can each agent actually access and do?
Maps instructions, data sources, tool permissions, and external connections per agent.
Which agents are handling sensitive data without approval?
Identifies agents with access to PII, code repos, production DBs, or financial systems.
Are unapproved AI tools running in my org?
Detects shadow coding agents, personal automation platforms connected to corporate data.
What is my overall AI risk posture?
Continuous risk scoring across all AI assets based on permissions, data access, and business exposure.
Which agents have excessive permissions?
Flags wildcard permissions (s3:*), missing HITL, and agents with unrestricted production write access.
What changed in my AI environment?
Tracks new agents, permission changes, and new tool connections since last known good state.
Where are my real attack paths — not just model vulnerabilities?
RedGraph maps how tools, prompts, and data combine to create exploitable surfaces specific to your environment.
Can an attacker pivot from one agent to sensitive systems?
Simulates lateral movement — e.g. support chat → Search skill → unauthorized SQL queries on your production DB.
What vulnerabilities only appear in production context?
Tests multi-turn attacks, tool hijacking, and indirect prompt injection through real agent configurations.
Is my agent behaving as intended right now?
Behavioral monitoring flags deviations from each agent's defined business purpose — not generic anomaly detection.
Is sensitive data leaving my environment?
Taint analysis traces PII and secrets from source to destination — blocks unauthorized egress in real time.
Are guardrails calibrated to each app's business purpose?
Adaptive guardrails adjust per agent — fewer false positives because they know what the agent is supposed to do.
Which AI tools are compliant with policy?
Enforces approved model lists, MCP allowlists, and AI usage policies across the full lifecycle.
Can I demonstrate AI security posture to auditors?
Audit logs, compliance reports, and policy lifecycle management for GDPR, CCPA, and internal standards.
What's my AI policy coverage gap?
Identifies agents operating outside governance boundaries before they become incidents.
Addressing your most pressing AI security challenges
Safe AI Adoption & Compliance
An unapproved coding agent runs on a developer machine with access to a code repository containing cloud credentials in the project root. Pillar flags it before any data leaves the endpoint.
A model outside the org's approved list reaches a production environment. Pillar identifies it and blocks inference until it clears the approval workflow.
An agent connects to an MCP server not on the organization's allowlist. Pillar surfaces the unauthorized connection and triggers a policy violation alert.
AI App Security
A coding agent skill contains shell execution patterns with network egress capabilities, enabling unrestricted command execution in production. Pillar detects the dangerous patterns in the tool definition before the skill reaches runtime.
An indirect injection in a support chat agent pivots through the Search tool to execute unauthorized queries against a production database. Pillar traces the injection across tool invocations and blocks execution.
An agent holds write access to production code repositories with no human-in-the-loop confirmation gate. Pillar scores it as a high-risk excessive agency violation and flags it for remediation.
Data Security
Taint analysis detects a customer-facing agent reading PII from a production database, serializing it, and posting it to an external webhook. Pillar captures the full egress path from source query to destination payload.
An MCP server returns an API key inside an error message response. Pillar intercepts it before it reaches an external log or client.
A container running an AI model holds wildcard cloud storage permissions on a bucket with customer PII and financial records. Pillar scores the permission combination as a critical exposure.
AI Infrastructure Security
A publicly accessible LLM proxy instance runs with no authentication and full access to internal APIs. Pillar detects the open endpoint during infrastructure scanning and flags it as a critical external exposure.
A model uses an unsafe serialization format and originates from an unverified publisher. Pillar blocks deployment after scanning model provenance against your approved list.
A coding agent downloads a compromised package and uses write access to production code repositories to push malicious code. Pillar detects the multi-step chain at the library download stage.
AI Attack Surface Management
Most red teaming tests models in isolation, missing the tools, data connections, and multi-agent workflows that create real attack paths in production. RedGraph maps your live AI environment as an attack graph, exposing exploitable paths across the full system that model-only testing never reaches.
A support chat agent connects to a Search tool, which pivots to an internal project management system. Pillar discovers the lateral movement path and scores the blast radius before attackers reach it.
A compromised agent propagates malicious instructions to downstream agents in an orchestration chain. Pillar catches the instruction at the first hop before it propagates.
Agentic AI Security
An agent chains tool calls across file system access, network egress, and a cloud storage API in a single session, moving data outside your environment without any single action triggering a threshold. Pillar tracks the full tool invocation sequence and flags the chain as a multi-step exfiltration pattern.
A compromised agent in an orchestration chain passes malicious instructions to downstream agents, propagating unauthorized behavior across the workflow. Pillar intercepts the poisoned instruction at the first handoff before it reaches dependent agents.
An agent inherits broad organizational permissions from its maker's identity and operates without scoped access controls. Pillar detects the delegated identity mismatch and flags the agent as operating outside its intended permission boundary.
“For the first time, our security team sees every model, dataset, and prompt in a single dashboard—no more chasing blind spots.”
"What impressed us most about Pillar was their holistic approach to Al security."
"We needed a security partner that not only pinpoints vulnerabilities but also helps remediate them automatically."
"By integrating Pillar’s advanced security guardrails, we ensure AI systems access only secure content, protecting our global customers."
See Pillar in action
We value your privacy. See our Privacy Policy for details.

In your 30 minute personal demo, you will learn how Pillar:
Seamlessly integrates with your code, AI and data platforms and provide full visibility into AI/ML assets.
Automatically scan and evaluates your AI assets for security risks.
Enables you to create and enforce AI security policies in development and runtime.
We've received your message, and we'll follow up via email shortly

